NVIDIA CUDA
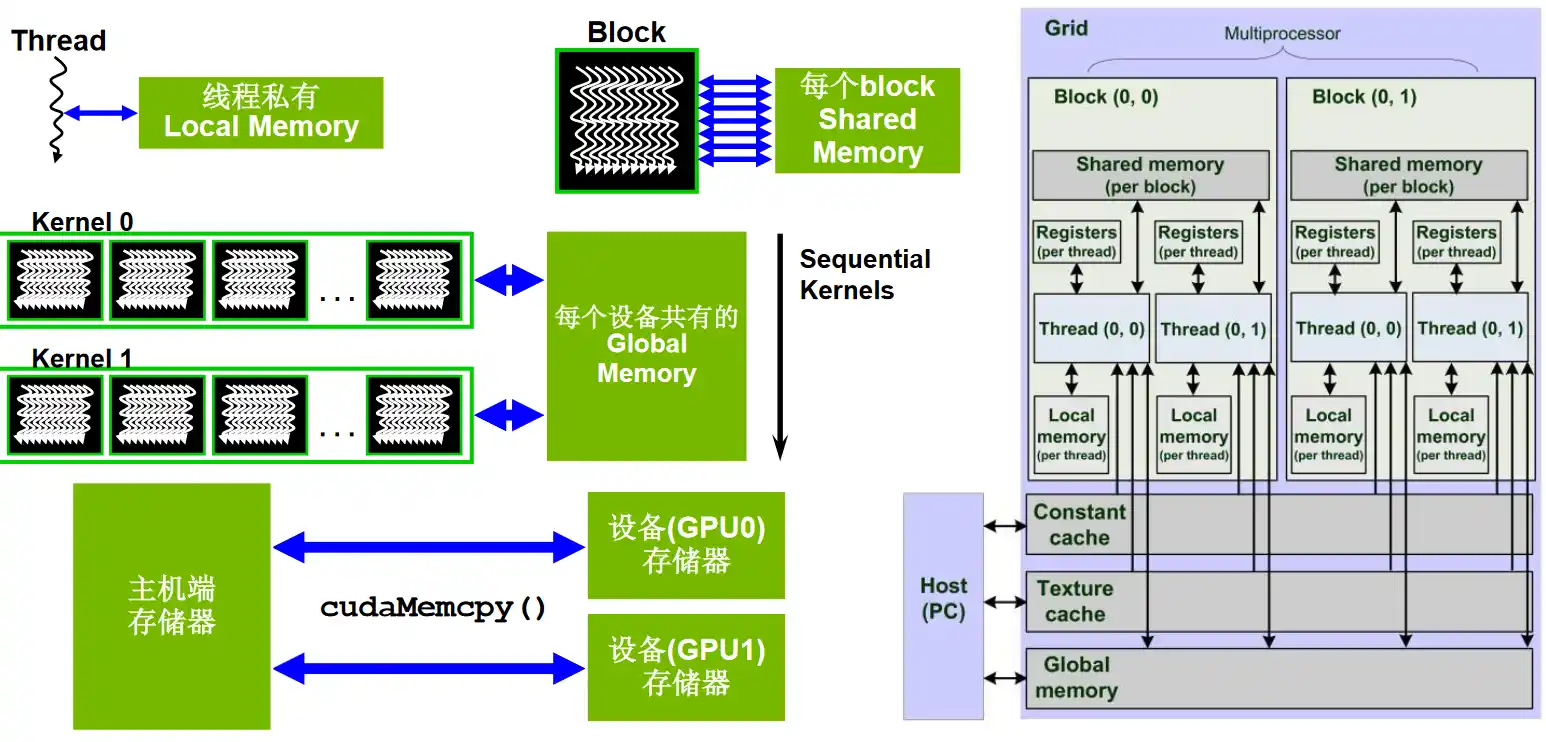
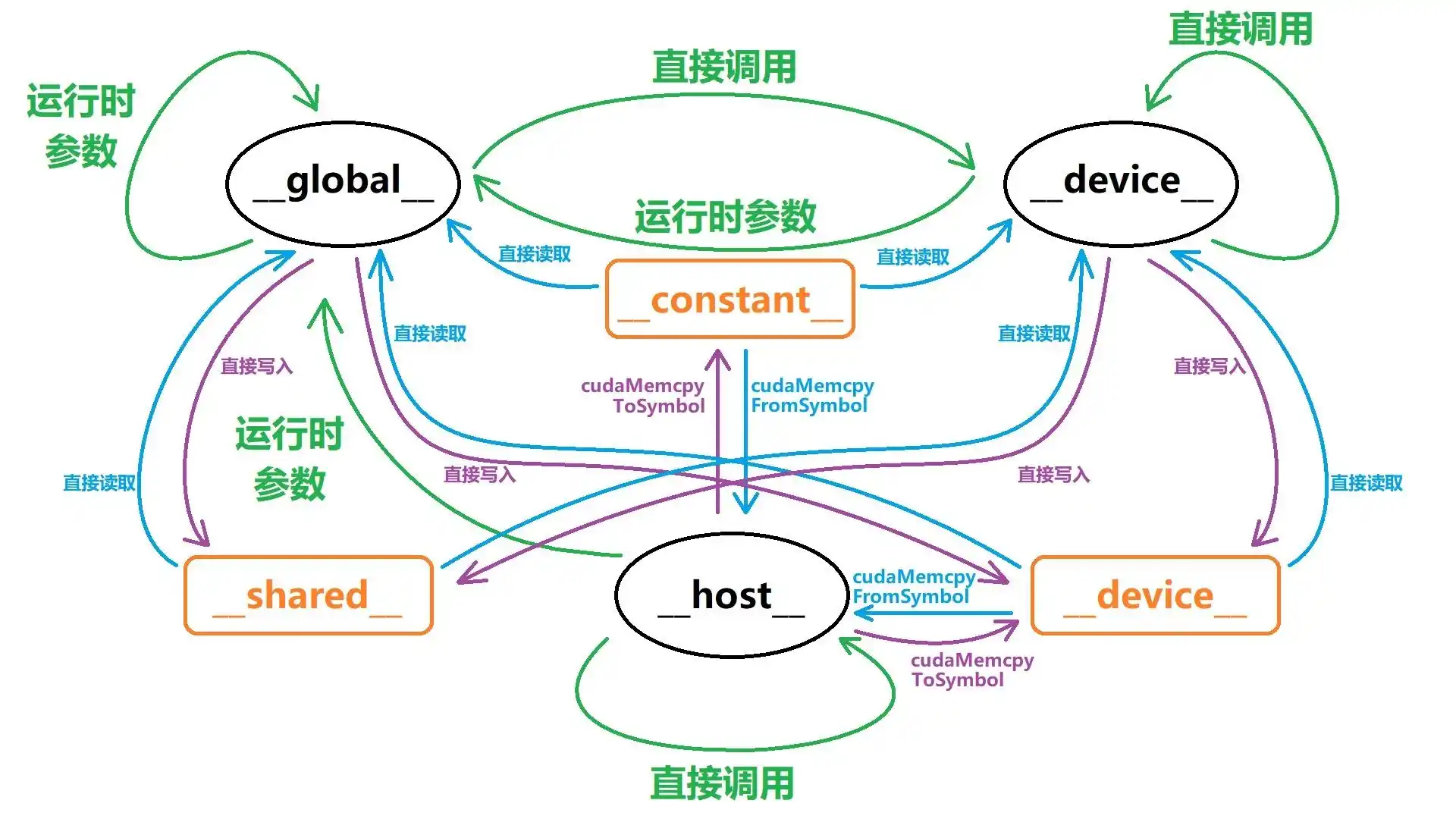
- Global memory:Grid 范围可见。不同 Block 之间通过全局内存交换数据是常见方式(但需要正确的同步手段,通常借助 Kernel 边界或原子/协作组等);
- Shared memory:Block 范围可见。只有同一 Block 的线程能读写同一块 Shared memory;不同 Block 彼此看不到对方的共享内存;
Programming Guide
Error Checking
#define CUDA_CHECK(expr_to_check) do { \
cudaError_t result = expr_to_check; \
if(result != cudaSuccess) \
{ \
fprintf(stderr, \
"CUDA Runtime Error: %s:%i:%d = %s\n", \
__FILE__, \
__LINE__, \
result,\
cudaGetErrorString(result)); \
} \
} while(0)
Timer
cudaEvent_t start, stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start);
cudaEventQuery(start);
// ...
cudaEventRecord(stop);
cudaEventSynchronize(stop);
float slapsed_time;
cudaEventElapsedTime(&elapsed_time, start, stop);
cudaEventDestroy(start);
cudaEventDestroy(stop);
LeetGPU
Easy
Vector Addition
import torch
# A, B, C are tensors on the GPU
def solve(A: torch.Tensor, B: torch.Tensor, C: torch.Tensor, N: int):
torch.add(A, B, out=C)
#include <cuda_runtime.h>
__global__ void vector_add(const float* A, const float* B, float* C, int N) {
int idx = blockDim.x * blockIdx.x + threadIdx.x;
if (idx < N) {
C[idx] = A[idx] + B[idx];
}
}
// A, B, C are device pointers (i.e. pointers to memory on the GPU)
extern "C" void solve(const float* A, const float* B, float* C, int N) {
int threadsPerBlock = 256;
int blocksPerGrid = (N + threadsPerBlock - 1) / threadsPerBlock;
vector_add<<<blocksPerGrid, threadsPerBlock>>>(A, B, C, N);
cudaDeviceSynchronize();
}
Matrix Multiplication
import torch
# A, B, C are tensors on the GPU
def solve(A: torch.Tensor, B: torch.Tensor, C: torch.Tensor, M: int, N: int, K: int):
torch.matmul(A, B, out=C)
#include <cuda_runtime.h>
__global__ void matrix_multiplication_kernel(const float* A, const float* B, float* C, int M, int N, int K) {
int x = blockDim.x * blockIdx.x + threadIdx.x; // col of C
int y = blockDim.y * blockIdx.y + threadIdx.y; // row if C
if (x >= K || y >= M) {
return;
}
float ans = 0.0;
for (int i = 0; i < N; ++i) {
ans += A[i + y * N] * B[x + i * K];
}
C[x + y * K] = ans;
}
// A, B, C are device pointers (i.e. pointers to memory on the GPU)
extern "C" void solve(const float* A, const float* B, float* C, int M, int N, int K) {
dim3 threadsPerBlock(16, 16);
dim3 blocksPerGrid((K + threadsPerBlock.x - 1) / threadsPerBlock.x,
(M + threadsPerBlock.y - 1) / threadsPerBlock.y);
matrix_multiplication_kernel<<<blocksPerGrid, threadsPerBlock>>>(A, B, C, M, N, K);
cudaDeviceSynchronize();
}
上面这种访问内存的方法,
-
对于单个线程内部,
x,y固定,i变化,则A的访问缓存友好; -
在 CUDA 硬件中,
threadIdx.x是变化最快的维度,因此同一个 Warp 内的线程,其x坐标必然是连续(或分段连续)的,而y坐标相对稳定。分析合并访问时,对于 Warp 级别,同一循环迭代(i相同),A访问的地址相同(广播),B访问的地址连续(合并访问)
A 的内存访问方式,依赖 L1 缓存广播,如果 N 过大,A 的一行可能超出 L1 缓存,导致缓存抖动,修改为下面这种共享内存的访问方式,
#include <cuda_runtime.h>
#define TILE_SIZE 16
__global__ void matrix_multiplication_kernel(const float* A, const float* B, float* C, int M, int N, int K) {
int row = blockDim.y * blockIdx.y + threadIdx.y; // [0, M)
int col = blockDim.x * blockIdx.x + threadIdx.x; // [0, K)
__shared__ float As[TILE_SIZE][TILE_SIZE + 1];
__shared__ float Bs[TILE_SIZE][TILE_SIZE + 1];
float acc = 0.0f;
int num_tiles = (N + TILE_SIZE - 1) / TILE_SIZE;
for (int i = 0; i < num_tiles; ++i) {
if (row < M && i * TILE_SIZE + threadIdx.x < N) {
As[threadIdx.y][threadIdx.x] = A[row * N + i * TILE_SIZE + threadIdx.x];
} else {
As[threadIdx.y][threadIdx.x] = 0.0f; // Boundary Filling
}
if (col < K && i * TILE_SIZE + threadIdx.y < N) {
Bs[threadIdx.y][threadIdx.x] = B[(i * TILE_SIZE + threadIdx.y) * K + col];
} else {
Bs[threadIdx.y][threadIdx.x] = 0.0f; // Boundary Filling
}
__syncthreads();
#pragma unroll
for (int k = 0; k < TILE_SIZE; ++k) {
acc += As[threadIdx.y][k] * Bs[k][threadIdx.x];
}
__syncthreads();
}
if (row < M && col < K) {
C[row * K + col] = acc;
}
}
// A, B, C are device pointers (i.e. pointers to memory on the GPU)
extern "C" void solve(const float* A, const float* B, float* C, int M, int N, int K) {
dim3 threadsPerBlock(16, 16);
dim3 blocksPerGrid((K + threadsPerBlock.x - 1) / threadsPerBlock.x,
(M + threadsPerBlock.y - 1) / threadsPerBlock.y);
matrix_multiplication_kernel<<<blocksPerGrid, threadsPerBlock>>>(A, B, C, M, N, K);
cudaDeviceSynchronize();
}
Matrix Transpose
import torch
# input, output are tensors on the GPU
def solve(input: torch.Tensor, output: torch.Tensor, rows: int, cols: int):
output[:] = input.T
# output.copy_(input.T) # PyTorch
#include <cuda_runtime.h>
__global__ void matrix_transpose_kernel(const float* input, float* output, int rows, int cols) {
int x = blockDim.x * blockIdx.x + threadIdx.x;
int y = blockDim.y * blockIdx.y + threadIdx.y;
if (x < cols && y < rows) {
output[y + rows * x] = input[x + cols * y];
}
}
// input, output are device pointers (i.e. pointers to memory on the GPU)
extern "C" void solve(const float* input, float* output, int rows, int cols) {
dim3 threadsPerBlock(16, 16);
dim3 blocksPerGrid((cols + threadsPerBlock.x - 1) / threadsPerBlock.x,
(rows + threadsPerBlock.y - 1) / threadsPerBlock.y);
matrix_transpose_kernel<<<blocksPerGrid, threadsPerBlock>>>(input, output, rows, cols);
cudaDeviceSynchronize();
}
Color Inversion
import torch
# image is a tensor on the GPU
def solve(image: torch.Tensor, width: int, height: int):
image = image.view(-1,4)
image[:, 0:3] = 255 - image[:, 0:3]
#include <cuda_runtime.h>
#define INV_MAGIC_NUM 0x00FFFFFF
__global__ void invert_kernel(unsigned char* image, int width, int height) {
const size_t size = width * height;
int idx = blockDim.x * blockIdx.x + threadIdx.x;
unsigned int *image4 = (unsigned int *)image; // Reverse order
if (idx < size) {
image4[idx] ^= INV_MAGIC_NUM;
}
}
// image_input, image_output are device pointers (i.e. pointers to memory on the GPU)
extern "C" void solve(unsigned char* image, int width, int height) {
int threadsPerBlock = 256;
int blocksPerGrid = (width * height + threadsPerBlock - 1) / threadsPerBlock;
invert_kernel<<<blocksPerGrid, threadsPerBlock>>>(image, width, height);
cudaDeviceSynchronize();
}
Matrix Addition
import torch
# A, B, C are tensors on the GPU
def solve(A: torch.Tensor, B: torch.Tensor, C: torch.Tensor, N: int):
torch.add(A, B, out=C)
#include <cuda_runtime.h>
__global__ void matrix_add(const float* A, const float* B, float* C, int N) {
int x = blockDim.x * blockIdx.x + threadIdx.x;
if (x < N * N) {
C[x] = A[x] + B[x];
}
}
// A, B, C are device pointers (i.e. pointers to memory on the GPU)
extern "C" void solve(const float* A, const float* B, float* C, int N) {
int threadsPerBlock = 256;
int blocksPerGrid = (N * N + threadsPerBlock - 1) / threadsPerBlock;
matrix_add<<<blocksPerGrid, threadsPerBlock>>>(A, B, C, N);
cudaDeviceSynchronize();
}
1D Convolution
import torch
import torch.nn.functional as F
# input, kernel, output are tensors on the GPU
def solve(
input: torch.Tensor,
kernel: torch.Tensor,
output: torch.Tensor,
input_size: int,
kernel_size: int,
):
assert input.device == kernel.device == output.device
assert input.dtype == kernel.dtype == output.dtype == torch.float32
assert input.numel() == input_size
assert kernel.numel() == kernel_size
output_size = input_size - kernel_size + 1
assert output_size >= 1
assert output.numel() == output_size
x = input.view(1, 1, input_size)
k = kernel.view(1, 1, kernel_size)
with torch.no_grad():
y = F.conv1d(x, k)
output.copy_(y.view(-1))
#include <cuda_runtime.h>
__global__ void convolution_1d_kernel(const float *input, const float *kernel,
float *output, int input_size,
int kernel_size) {
int x = blockDim.x * blockIdx.x + threadIdx.x;
if (x >= input_size - kernel_size + 1) {
return;
}
float output_kernel = 0.0;
for (int i = 0; i < kernel_size; ++i) {
output_kernel += kernel[i] * input[x + i];
}
output[x] = output_kernel;
}
// input, kernel, output are device pointers (i.e. pointers to memory on the GPU)
extern "C" void solve(const float* input, const float* kernel, float* output, int input_size,
int kernel_size) {
int output_size = input_size - kernel_size + 1;
int threadsPerBlock = 256;
int blocksPerGrid = (output_size + threadsPerBlock - 1) / threadsPerBlock;
convolution_1d_kernel<<<blocksPerGrid, threadsPerBlock>>>(input, kernel, output, input_size,
kernel_size);
cudaDeviceSynchronize();
}
下面使用共享内存缓存卷积核,
#include <cuda_runtime.h>
__global__ void convolution_1d_kernel(const float *__restrict__ input, const float *__restrict__ kernel,
float *__restrict__ output, int input_size, int kernel_size) {
int x = blockDim.x * blockIdx.x + threadIdx.x;
if (x >= input_size - kernel_size + 1) {
return;
}
extern __shared__ float shared_kernel[];
for (int i = threadIdx.x; i < kernel_size; ++i) {
shared_kernel[i] = kernel[i];
}
__syncthreads();
float output_kernel = 0.0f;
#pragma unroll
for (int i = 0; i < kernel_size; ++i) {
output_kernel += shared_kernel[i] * __ldg(&input[x + i]);
}
output[x] = output_kernel;
}
// input, kernel, output are device pointers (i.e. pointers to memory on the GPU)
extern "C" void solve(const float* input, const float* kernel, float* output, int input_size,
int kernel_size) {
int output_size = input_size - kernel_size + 1;
int threadsPerBlock = 256;
int blocksPerGrid = (output_size + threadsPerBlock - 1) / threadsPerBlock;
size_t shared_mem_size = kernel_size * sizeof(float);
convolution_1d_kernel<<<blocksPerGrid, threadsPerBlock, shared_mem_size>>>(input, kernel, output, input_size,
kernel_size);
cudaDeviceSynchronize();
}
Reverse Array
import torch
# input is a tensor on the GPU
def solve(input: torch.Tensor, N: int):
input.copy_(torch.flip(input, dims=[0]))
#include <cuda_runtime.h>
__global__ void reverse_array(float* input, int N) {
int x = blockIdx.x * blockDim.x + threadIdx.x;
if (x < N / 2) {
float tmp = 0.0;
tmp = input[x];
input[x] = input[N - 1 - x];
input[N - 1 - x] = tmp;
}
}
// input is device pointer
extern "C" void solve(float* input, int N) {
int threadsPerBlock = 256;
int blocksPerGrid = (N + threadsPerBlock - 1) / threadsPerBlock;
reverse_array<<<blocksPerGrid, threadsPerBlock>>>(input, N);
cudaDeviceSynchronize();
}
ReLU
import torch
# input, output are tensors on the GPU
def solve(input: torch.Tensor, output: torch.Tensor, N: int):
torch.clamp(input, min=0, out=output)
#include <cuda_runtime.h>
__global__ void relu_kernel(const float* input, float* output, int N) {
int x = blockDim.x * blockIdx.x + threadIdx.x;
if (x < N) {
output[x] = input[x] > 0 ? input[x] : 0;
}
}
// input, output are device pointers (i.e. pointers to memory on the GPU)
extern "C" void solve(const float* input, float* output, int N) {
int threadsPerBlock = 256;
int blocksPerGrid = (N + threadsPerBlock - 1) / threadsPerBlock;
relu_kernel<<<blocksPerGrid, threadsPerBlock>>>(input, output, N);
cudaDeviceSynchronize();
}
Leaky ReLU
import torch
# input, output are tensors on the GPU
def solve(input: torch.Tensor, output: torch.Tensor, N: int):
output.copy_(torch.where(input >= 0, input, 0.01 * input))
#include <cuda_runtime.h>
__global__ void leaky_relu_kernel(const float* input, float* output, int N) {
int x = blockDim.x * blockIdx.x + threadIdx.x;
if (x < N) {
output[x] = input[x] > 0.0f ? input[x] : 0.01f * input[x];
}
}
// input, output are device pointers (i.e. pointers to memory on the GPU)
extern "C" void solve(const float* input, float* output, int N) {
int threadsPerBlock = 256;
int blocksPerGrid = (N + threadsPerBlock - 1) / threadsPerBlock;
leaky_relu_kernel<<<blocksPerGrid, threadsPerBlock>>>(input, output, N);
cudaDeviceSynchronize();
}
Rainbow Table
import torch
def fnv1a_hash(x: torch.Tensor) -> torch.Tensor:
FNV_PRIME = 16777619
OFFSET_BASIS = 2166136261
x_int = x.to(torch.int64)
hash_val = torch.full_like(x_int, OFFSET_BASIS, dtype=torch.int64)
for byte_pos in range(4):
byte = (x_int >> (byte_pos * 8)) & 0xFF
hash_val = (hash_val ^ byte) * FNV_PRIME
hash_val = hash_val & 0xFFFFFFFF
return hash_val.to(torch.int32)
# input, output are tensors on the GPU
def solve(input: torch.Tensor, output: torch.Tensor, N: int, R: int):
for _ in range(R):
input = fnv1a_hash(input)
output.copy_(input)
#include <cuda_runtime.h>
__device__ unsigned int fnv1a_hash(int input) {
const unsigned int FNV_PRIME = 16777619;
const unsigned int OFFSET_BASIS = 2166136261;
unsigned int hash = OFFSET_BASIS;
for (int byte_pos = 0; byte_pos < 4; byte_pos++) {
unsigned char byte = (input >> (byte_pos * 8)) & 0xFF;
hash = (hash ^ byte) * FNV_PRIME;
}
return hash;
}
__global__ void fnv1a_hash_kernel(const int* input, unsigned int* output, int N, int R) {
int x = blockDim.x * blockIdx.x + threadIdx.x;
if (x < N) {
output[x] = input[x];
for (int i = 0; i < R; ++i) {
output[x] = fnv1a_hash(output[x]);
}
}
}
// input, output are device pointers (i.e. pointers to memory on the GPU)
extern "C" void solve(const int* input, unsigned int* output, int N, int R) {
int threadsPerBlock = 256;
int blocksPerGrid = (N + threadsPerBlock - 1) / threadsPerBlock;
fnv1a_hash_kernel<<<blocksPerGrid, threadsPerBlock>>>(input, output, N, R);
cudaDeviceSynchronize();
}
Matrix Copy
import torch
# A, B are tensors on the GPU
def solve(A: torch.Tensor, B: torch.Tensor, N: int):
B.copy_(A)
#include <cuda_runtime.h>
__global__ void copy_matrix_kernel(const float* A, float* B, int N) {
int x = blockDim.x * blockIdx.x + threadIdx.x;
if (x < N * N) {
B[x] = A[x];
}
}
// A, B are device pointers (i.e. pointers to memory on the GPU)
extern "C" void solve(const float* A, float* B, int N) {
int total = N * N;
int threadsPerBlock = 256;
int blocksPerGrid = (total + threadsPerBlock - 1) / threadsPerBlock;
copy_matrix_kernel<<<blocksPerGrid, threadsPerBlock>>>(A, B, N);
cudaDeviceSynchronize();
}
////////////////////////////////////////////////////////////////////////////////
#include <cuda_runtime.h>
extern "C" void solve(const float* A, float* B, int N) {
size_t bytes = N * N * sizeof(float);
cudaMemcpy(B, A, bytes, cudaMemcpyDeviceToDevice);
}
Simple Inference
import torch
import torch.nn as nn
# input, model, and output are on the GPU
def solve(input: torch.Tensor, model: nn.Module, output: torch.Tensor):
with torch.no_grad():
output.copy_(model(input))
Count Array Element
import torch
# input, output are tensors on the GPU
def solve(input: torch.Tensor, output: torch.Tensor, N: int, K: int):
output.copy_(torch.sum(input == K))
#include <cuda_runtime.h>
/******************************************************************************/
__global__ void count_equal_kernel(const int* input, int* output, int N, int K) {
int x = blockDim.x * blockIdx.x + threadIdx.x;
if (x < N) {
if (input[x] == K) {
atomicAdd(output, 1);
}
}
}
/******************************************************************************/
// 共享内存 + 并行规约
__global__ void count_equal_kernel(const int* input, int* output, int N, int K) {
int x = blockDim.x * blockIdx.x + threadIdx.x;
int tid = threadIdx.x;
__shared__ int block_cnt[256];
int local_cnt = 0;
if (x < N && input[x] == K) {
local_cnt = 1;
}
block_cnt[tid] = local_cnt;
__syncthreads();
for (int stride = blockDim.x / 2; stride > 0; stride >>= 1) {
if (tid < stride) {
block_cnt[tid] += block_cnt[tid + stride];
}
__syncthreads();
}
if (tid == 0 && block_cnt[0] > 0) {
atomicAdd(output, block_cnt[0]);
}
}
/******************************************************************************/
// warp 内部 Shuffle 规约
__device__ __forceinline__ int warp_reduce_sum(int val) {
for (int offset = 16; offset > 0; offset >>= 1) {
val += __shfl_down_sync(0xFFFFFFFF, val, offset);
}
return val;
}
__global__ void count_equal_kernel(const int* input, int* output, int N, int K) {
int x = blockDim.x * blockIdx.x + threadIdx.x;
int tid = threadIdx.x;
int lane = tid % 32;
int warp_id = tid / 32;
int local_cnt = (x < N && input[x] == K) ? 1 : 0;
local_cnt = warp_reduce_sum(local_cnt);
__shared__ int warp_cnt[8]; // 256 / 32 = 8 warps
if (lane == 0) {
warp_cnt[warp_id] = local_cnt;
}
__syncthreads();
if (warp_id == 0) {
int val = (lane < 8) ? warp_cnt[lane] : 0;
val = warp_reduce_sum(val);
if (lane == 0 && val > 0) {
atomicAdd(output, val);
}
}
}
/******************************************************************************/
// input, output are device pointers (i.e. pointers to memory on the GPU)
extern "C" void solve(const int* input, int* output, int N, int K) {
int threadsPerBlock = 256;
int blocksPerGrid = (N + threadsPerBlock - 1) / threadsPerBlock;
count_equal_kernel<<<blocksPerGrid, threadsPerBlock>>>(input, output, N, K);
cudaDeviceSynchronize();
}
Count 2D Array Element
import torch
# input, output are tensors on the GPU
def solve(input: torch.Tensor, output: torch.Tensor, N: int, M: int, K: int):
output.copy_(torch.sum(input.flatten() == K))
#include <cuda_runtime.h>
__global__ void count_2d_equal_kernel(const int* input, int* output, int N, int M, int K) {
int x = blockDim.x * blockIdx.x + threadIdx.x;
int y = blockDim.y * blockIdx.y + threadIdx.y;
if (y < N && x < M && input[y*M + x] == K) {
atomicAdd(output, 1);
}
}
// input, output are device pointers (i.e. pointers to memory on the GPU)
extern "C" void solve(const int* input, int* output, int N, int M, int K) {
dim3 threadsPerBlock(16, 16);
dim3 blocksPerGrid((M + threadsPerBlock.x - 1) / threadsPerBlock.x,
(N + threadsPerBlock.y - 1) / threadsPerBlock.y);
count_2d_equal_kernel<<<blocksPerGrid, threadsPerBlock>>>(input, output, N, M, K);
cudaDeviceSynchronize();
}
Sigmoid Linear Unit
import torch
# input, output are tensors on the GPU
def solve(input: torch.Tensor, output: torch.Tensor, N: int):
torch.mul(input, torch.sigmoid(input), out=output)
#include <cuda_runtime.h>
__global__ void silu_kernel(const float* input, float* output, int N) {
int x = blockDim.x * blockIdx.x + threadIdx.x;
if (x < N) {
output[x] = input[x] / (1 + expf(-input[x]));
}
}
// input, output are device pointers
extern "C" void solve(const float* input, float* output, int N) {
int threadsPerBlock = 256;
int blocksPerGrid = (N + threadsPerBlock - 1) / threadsPerBlock;
silu_kernel<<<blocksPerGrid, threadsPerBlock>>>(input, output, N);
cudaDeviceSynchronize();
}
Swish-Gated Linear Unit
import torch
# input, output are tensors on the GPU
def solve(input: torch.Tensor, output: torch.Tensor, N: int):
x1, x2 = input[:N//2], input[N//2:]
torch.mul(x1 * torch.nn.functional.sigmoid(x1), x2, out=output)
#include <cuda_runtime.h>
__global__ void swiglu_kernel(const float* input, float* output, int halfN) {
int x = blockDim.x * blockIdx.x + threadIdx.x;
if (x < halfN) {
float silu = input[x] * (1 / (1 + expf(-input[x])));
output[x] = silu * input[x+ halfN];
}
}
// input, output are device pointers
extern "C" void solve(const float* input, float* output, int N) {
int halfN = N / 2;
int threadsPerBlock = 256;
int blocksPerGrid = (halfN + threadsPerBlock - 1) / threadsPerBlock;
swiglu_kernel<<<blocksPerGrid, threadsPerBlock>>>(input, output, halfN);
cudaDeviceSynchronize();
}
Value Clipping
import torch
# input, output are tensors on the GPU
def solve(input: torch.Tensor, output: torch.Tensor, lo: float, hi: float, N: int):
torch.clamp(input, lo, hi, out=output)
#include <cuda_runtime.h>
__global__ void clip_kernel(const float* input, float* output, float lo, float hi, int N) {
int x = blockDim.x * blockIdx.x + threadIdx.x;
if (x < N) {
output[x] = fmaxf(fminf(input[x], hi), lo);
}
}
// input, output are device pointers
extern "C" void solve(const float* input, float* output, float lo, float hi, int N) {
int threadsPerBlock = 256;
int blocksPerGrid = (N + threadsPerBlock - 1) / threadsPerBlock;
clip_kernel<<<blocksPerGrid, threadsPerBlock>>>(input, output, lo, hi, N);
cudaDeviceSynchronize();
}
Interleave Arrays
import torch
# A, B, output are tensors on the GPU
def solve(A: torch.Tensor, B: torch.Tensor, output: torch.Tensor, N: int):
# output[0::2] = A
# output[1::2] = B
output.data = torch.stack([A, B], dim=1).flatten()
#include <cuda_runtime.h>
__global__ void interleave_kernel(const float* A, const float* B, float* output, int N) {
int x = blockDim.x * blockIdx.x + threadIdx.x;
if (x < N) {
output[x * 2] = A[x];
output[2 * x + 1] = B[x];
}
}
// A, B, output are device pointers (i.e. pointers to memory on the GPU)
extern "C" void solve(const float* A, const float* B, float* output, int N) {
int threadsPerBlock = 256;
int blocksPerGrid = (N + threadsPerBlock - 1) / threadsPerBlock;
interleave_kernel<<<blocksPerGrid, threadsPerBlock>>>(A, B, output, N);
cudaDeviceSynchronize();
}
Gaussian Error Gated Linear Unit
import torch
import torch.nn.functional as F
# input, output are tensors on the GPU
def solve(input: torch.Tensor, output: torch.Tensor, N: int):
output.copy_(input[:N//2] * F.gelu(input[N//2:]))
#include <cuda_runtime.h>
__global__ void geglu_kernel(const float* input, float* output, int halfN) {
int x = blockDim.x * blockIdx.x + threadIdx.x;
if (x < halfN){
output[x] = input[x] * 0.5f * input[x + halfN] * (1.0f + erff(input[x + halfN] * 0.7071067811865475f));
}
}
// input, output are device pointers
extern "C" void solve(const float* input, float* output, int N) {
int halfN = N / 2;
int threadsPerBlock = 256;
int blocksPerGrid = (halfN + threadsPerBlock - 1) / threadsPerBlock;
geglu_kernel<<<blocksPerGrid, threadsPerBlock>>>(input, output, halfN);
cudaDeviceSynchronize();
}
RGB to Grayscale
import torch
# input, output are tensors on the GPU
def solve(input: torch.Tensor, output: torch.Tensor, width: int, height: int):
output[:] = 0.299 * input[0::3] + 0.587 * input[1::3] + 0.114 * input[2::3]
#include <cuda_runtime.h>
__global__ void rgb_to_grayscale_kernel(const float* input, float* output, int width, int height) {
int x = blockDim.x * blockIdx.x + threadIdx.x;
if (x < width * height) {
int x3 = x * 3;
output[x] = input[x3] * 0.299 + input[x3 + 1] * 0.587 + input[x3 + 2] * 0.114;
}
}
// input, output are device pointers
extern "C" void solve(const float* input, float* output, int width, int height) {
int total_pixels = width * height;
int threadsPerBlock = 256;
int blocksPerGrid = (total_pixels + threadsPerBlock - 1) / threadsPerBlock;
rgb_to_grayscale_kernel<<<blocksPerGrid, threadsPerBlock>>>(input, output, width, height);
cudaDeviceSynchronize();
}
Sigmoid Activation
import torch
# X, Y are tensors on the GPU
def solve(X: torch.Tensor, Y: torch.Tensor, N: int):
torch.sigmoid(X, out=Y)
#include <cuda_runtime.h>
#include <math.h>
__global__ void sigmoid_kernel(const float* X, float* Y, int N) {
int x = blockDim.x * blockIdx.x + threadIdx.x;
if (x >= N) {
return;
}
Y[x] = 1 / (1 + expf(-X[x]));
}
// X, Y are device pointers (i.e. pointers to memory on the GPU)
extern "C" void solve(const float* X, float* Y, int N) {
int threadsPerBlock = 256;
int blocksPerGrid = (N + threadsPerBlock - 1) / threadsPerBlock;
sigmoid_kernel<<<blocksPerGrid, threadsPerBlock>>>(X, Y, N);
cudaDeviceSynchronize();
}
Medium
Reduction
import torch
# input, output are tensors on the GPU
def solve(input: torch.Tensor, output: torch.Tensor, N: int):
output.copy_(input.sum())
#include <cuda_runtime.h>
#define BLOCK_SIZE 256
#define ELEMENTS_PER_THREAD 8
// 蝶形规约
__device__ __forceinline__ float warpReduceSum(float val) {
val += __shfl_down_sync(0xFFFFFFFF, val, 16);
val += __shfl_down_sync(0xFFFFFFFF, val, 8);
val += __shfl_down_sync(0xFFFFFFFF, val, 4);
val += __shfl_down_sync(0xFFFFFFFF, val, 2);
val += __shfl_down_sync(0xFFFFFFFF, val, 1);
return val; // lane 0
}
__global__ __launch_bounds__(BLOCK_SIZE)
void reduceKernel(const float* __restrict__ input, float* __restrict__ output, int N) {
__shared__ float warpSums[BLOCK_SIZE / 32]; // 8 float
float sum = 0.0f;
int base = blockIdx.x * (BLOCK_SIZE * ELEMENTS_PER_THREAD) + threadIdx.x;
#pragma unroll
for (int i = 0; i < ELEMENTS_PER_THREAD; ++i) {
int idx = base + i * BLOCK_SIZE;
if (idx < N) {
sum += input[idx];
}
}
sum = warpReduceSum(sum);
int lane = threadIdx.x & 31;
int wid = threadIdx.x >> 5;
if (lane == 0) {
warpSums[wid] = sum;
}
__syncthreads();
if (wid == 0) {
sum = (threadIdx.x < (BLOCK_SIZE / 32)) ? warpSums[lane] : 0.0f;
sum = warpReduceSum(sum);
if (threadIdx.x == 0) {
output[blockIdx.x] = sum;
}
}
}
__global__ __launch_bounds__(BLOCK_SIZE)
void reduceFinalKernel(const float* __restrict__ input, float* __restrict__ output, int N) {
__shared__ float warpSums[BLOCK_SIZE / 32];
float sum = 0.0f;
for (int i = blockIdx.x * BLOCK_SIZE + threadIdx.x; i < N; i += blockDim.x * gridDim.x) {
sum += input[i];
}
sum = warpReduceSum(sum);
int lane = threadIdx.x & 31;
int wid = threadIdx.x >> 5;
if (lane == 0) {
warpSums[wid] = sum;
}
__syncthreads();
if (wid == 0) {
sum = (threadIdx.x < (BLOCK_SIZE / 32)) ? warpSums[lane] : 0.0f;
sum = warpReduceSum(sum);
if (threadIdx.x == 0) {
atomicAdd(output, sum);
}
}
}
extern "C" void solve(const float* input, float* output, int N) {
if (N <= 0) {
cudaMemset(output, 0, sizeof(float));
return;
}
int elemsPerBlock = BLOCK_SIZE * ELEMENTS_PER_THREAD; // 256 * 8 = 2048
int numBlocks = (N + elemsPerBlock - 1) / elemsPerBlock; // Round up
if (numBlocks == 1) {
reduceKernel<<<1, BLOCK_SIZE>>>(input, output, N);
} else {
float* partial = nullptr;
cudaMalloc(&partial, numBlocks * sizeof(float));
reduceKernel<<<numBlocks, BLOCK_SIZE>>>(input, partial, N);
int finalBlocks = (numBlocks + elemsPerBlock - 1) / elemsPerBlock;
if (finalBlocks <= 1) {
reduceKernel<<<1, BLOCK_SIZE>>>(partial, output, numBlocks);
} else {
cudaMemset(output, 0, sizeof(float));
reduceFinalKernel<<<finalBlocks, BLOCK_SIZE>>>(partial, output, numBlocks);
}
cudaFree(partial);
}
}
Softmax
import torch
# input, output are tensors on the GPU
def solve(input: torch.Tensor, output: torch.Tensor, N: int):
output.copy_(torch.nn.functional.softmax(input, dim=-1))
#include <cuda_runtime.h>
#include <math.h>
#define BLOCK_SIZE 256
#define NUM_WARPS (BLOCK_SIZE / 32)
__device__ __forceinline__ float warpReduceMax(float val) {
val = fmaxf(val, __shfl_down_sync(0xFFFFFFFF, val, 16));
val = fmaxf(val, __shfl_down_sync(0xFFFFFFFF, val, 8));
val = fmaxf(val, __shfl_down_sync(0xFFFFFFFF, val, 4));
val = fmaxf(val, __shfl_down_sync(0xFFFFFFFF, val, 2));
val = fmaxf(val, __shfl_down_sync(0xFFFFFFFF, val, 1));
return val;
}
__device__ __forceinline__ float warpReduceSum(float val) {
val += __shfl_down_sync(0xFFFFFFFF, val, 16);
val += __shfl_down_sync(0xFFFFFFFF, val, 8);
val += __shfl_down_sync(0xFFFFFFFF, val, 4);
val += __shfl_down_sync(0xFFFFFFFF, val, 2);
val += __shfl_down_sync(0xFFFFFFFF, val, 1);
return val;
}
// ============ Kernel 1: Parallel Max Reduction ============
__global__ __launch_bounds__(BLOCK_SIZE)
void reduceMaxKernel(const float* __restrict__ input, float* __restrict__ output, int N) {
__shared__ float sdata[NUM_WARPS];
float maxVal = -INFINITY;
for (int i = blockIdx.x * blockDim.x + threadIdx.x; i < N; i += blockDim.x * gridDim.x) {
maxVal = fmaxf(maxVal, input[i]);
}
maxVal = warpReduceMax(maxVal);
int lane = threadIdx.x & 31;
int wid = threadIdx.x >> 5;
if (lane == 0) sdata[wid] = maxVal;
__syncthreads();
if (wid == 0) {
maxVal = (lane < NUM_WARPS) ? sdata[lane] : -INFINITY;
maxVal = warpReduceMax(maxVal);
if (lane == 0) output[blockIdx.x] = maxVal;
}
}
// ============ Kernel 2: exp(x - max) and partial sum ============
__global__ __launch_bounds__(BLOCK_SIZE)
void expAndSumKernel(const float* __restrict__ input, float* __restrict__ output,
const float* __restrict__ d_max, float* __restrict__ partialSums, int N) {
__shared__ float sdata[NUM_WARPS];
float maxVal = d_max[0];
float localSum = 0.0f;
for (int i = blockIdx.x * blockDim.x + threadIdx.x; i < N; i += blockDim.x * gridDim.x) {
float val = expf(input[i] - maxVal);
output[i] = val;
localSum += val;
}
localSum = warpReduceSum(localSum);
int lane = threadIdx.x & 31;
int wid = threadIdx.x >> 5;
if (lane == 0) sdata[wid] = localSum;
__syncthreads();
if (wid == 0) {
localSum = (lane < NUM_WARPS) ? sdata[lane] : 0.0f;
localSum = warpReduceSum(localSum);
if (lane == 0) partialSums[blockIdx.x] = localSum;
}
}
// ============ Kernel 3: Reduce partial sums ============
__global__ __launch_bounds__(BLOCK_SIZE)
void reduceSumKernel(const float* __restrict__ input, float* __restrict__ output, int N) {
__shared__ float sdata[NUM_WARPS];
float sum = 0.0f;
for (int i = blockIdx.x * blockDim.x + threadIdx.x; i < N; i += blockDim.x * gridDim.x) {
sum += input[i];
}
sum = warpReduceSum(sum);
int lane = threadIdx.x & 31;
int wid = threadIdx.x >> 5;
if (lane == 0) sdata[wid] = sum;
__syncthreads();
if (wid == 0) {
sum = (lane < NUM_WARPS) ? sdata[lane] : 0.0f;
sum = warpReduceSum(sum);
if (lane == 0) output[0] = sum;
}
}
// ============ Kernel 4: Normalize ============
__global__ __launch_bounds__(BLOCK_SIZE)
void normalizeKernel(float* __restrict__ data, const float* __restrict__ d_sum, int N) {
float invSum = 1.0f / d_sum[0];
for (int i = blockIdx.x * blockDim.x + threadIdx.x; i < N; i += blockDim.x * gridDim.x) {
data[i] *= invSum;
}
}
//XXX Unused
__global__ void softmax_kernel(const float* input, float* output, int N) {}
extern "C" void solve(const float* input, float* output, int N) {
if (N <= 0) return;
int numBlocks = min((N + BLOCK_SIZE - 1) / BLOCK_SIZE, 1024);
float *d_partial, *d_scalar;
cudaMalloc(&d_partial, numBlocks * sizeof(float));
cudaMalloc(&d_scalar, sizeof(float));
// Step 1: Find max(input)
reduceMaxKernel<<<numBlocks, BLOCK_SIZE>>>(input, d_partial, N);
reduceMaxKernel<<<1, BLOCK_SIZE>>>(d_partial, d_scalar, numBlocks);
// Step 2: Compute exp(x_i - max) → output, and partial sums
expAndSumKernel<<<numBlocks, BLOCK_SIZE>>>(input, output, d_scalar, d_partial, N);
// Step 3: Reduce partial sums → total sum
reduceSumKernel<<<1, BLOCK_SIZE>>>(d_partial, d_scalar, numBlocks);
// Step 4: Normalize output[i] /= sum
normalizeKernel<<<numBlocks, BLOCK_SIZE>>>(output, d_scalar, N);
cudaFree(d_partial);
cudaFree(d_scalar);
}
Softmax Attention
import torch
import torch.nn.functional as F
# Q, K, V, output are tensors on the GPU
def solve(Q: torch.Tensor, K: torch.Tensor, V: torch.Tensor, output: torch.Tensor,
M: int, N: int, d: int):
output.copy_((F.softmax(Q @ K.T / (d ** 0.5), dim=1)@V))
#include <cuda_runtime.h>
#include <device_launch_parameters.h>
#include <math.h>
#include <stdio.h>
#define CUDA_CHECK(expr_to_check) \
do { \
cudaError_t result = expr_to_check; \
if (result != cudaSuccess) { \
fprintf(stderr, "CUDA Runtime Error: %s:%i:%d = %s\n", __FILE__, \
__LINE__, result, cudaGetErrorString(result)); \
} \
} while (0)
__device__ __forceinline__ float warp_reduce_max(float val) {
#pragma unroll
for (int offset = warpSize / 2; offset > 0; offset >>= 1) {
val = fmaxf(val, __shfl_down_sync(0xffffffff, val, offset));
}
return val;
}
__device__ __forceinline__ float warp_reduce_sum(float val) {
#pragma unroll
for (int offset = warpSize / 2; offset > 0; offset >>= 1) {
val += __shfl_down_sync(0xffffffff, val, offset);
}
return val;
}
/**
* Kernel1:
* Q * K^T -> Scores
* (M * d)(N * d) -> (M * N)
*
*/
__global__ void matmul_qk(const float *Q, const float *K, float *Scores, int M,
int N, int d) {
int x = blockDim.x * blockIdx.x + threadIdx.x; // [0, N)
int y = blockDim.y * blockIdx.y + threadIdx.y; // [0, M)
if (x >= N || y >= M) {
return;
}
float dot = 0.0f;
for (int i = 0; i < d; ++i) {
dot += Q[y * d + i] * K[x * d + i];
}
Scores[y * N + x] = dot / sqrtf((float)d);
}
/**
* Kernel2: Row-wise Softmax on Scores[M*N]
* Each block processes one row (M blocks total)
* Uses shared memory for block-level reduction
*/
__global__ void softmax_kernel(float *Scores, int M, int N) {
int row = blockIdx.x;
if (row >= M) {
return;
}
// Find row max
int tid = threadIdx.x;
int lane = tid % warpSize;
int warp_id = tid / warpSize;
int num_warps = (blockDim.x + warpSize - 1) / warpSize;
/**
* Thread 0: col = 0, 256, 512, 768
* Thread 1: col = 1, 257, 513, 769
* ...
* Thread 255: col = 255, 511, 767, 1023
*/
float max_val = -INFINITY;
for (int col = tid; col < N; col += blockDim.x) {
max_val = fmaxf(max_val, Scores[row * N + col]);
}
// // Block-level reduction for max
// extern __shared__ float shared[];
// shared[tid] = max_val;
// __syncthreads();
// for (int stride = blockDim.x >> 1; stride > 0; stride >>= 1) {
// if (tid < stride) {
// shared[tid] = fmaxf(shared[tid], shared[tid + stride]);
// }
// __syncthreads();
// }
// max_val = shared[0];
max_val = warp_reduce_max(max_val);
extern __shared__ float shared[];
if (lane == 0) {
shared[warp_id] = max_val; // lan0 contains max value
}
__syncthreads();
if (warp_id == 0) {
float val = (tid < num_warps) ? shared[tid] : -INFINITY;
val = warp_reduce_max(val);
if (tid == 0) {
shared[0] = val;
}
}
__syncthreads();
max_val = shared[0];
// Compute exp(x - max) and sum
float sum_val = 0.0f;
for (int col = tid; col < N; col += blockDim.x) {
float exp_val = expf(Scores[row * N + col] - max_val);
Scores[row * N + col] = exp_val;
sum_val += exp_val;
}
// // Block-level reduction for sum
// shared[tid] = sum_val;
// __syncthreads();
// for (int stride = blockDim.x >> 1; stride > 0; stride >>= 1) {
// if (tid < stride) {
// shared[tid] += shared[tid + stride];
// }
// __syncthreads();
// }
// sum_val = shared[0];
// __syncthreads();
sum_val = warp_reduce_sum(sum_val);
if (lane == 0) {
shared[warp_id] = sum_val;
}
__syncthreads();
if (warp_id == 0) {
float val = (tid < num_warps) ? shared[tid] : 0.0f;
val = warp_reduce_sum(val);
if (tid == 0) {
shared[0] = val;
}
}
__syncthreads();
float total_sum = shared[0];
// Normalize
float inv_sum = 1.0f / total_sum;
for (int col = tid; col < N; col += blockDim.x) {
Scores[row * N + col] *= inv_sum;
}
}
/**
* Kernel3: Scores * V -> output
* Scores: [M, N], V: [N, d] -> output: [M, d]
*/
__global__ void matmul_sv(const float *Scores, const float *V, float *output,
int M, int N, int d) {
int col = blockDim.x * blockIdx.x + threadIdx.x; // [0, d)
int row = blockDim.y * blockIdx.y + threadIdx.y; // [0, M)
if (col >= d || row >= M) {
return;
}
float sum = 0.0f;
for (int k = 0; k < N; ++k) {
sum += Scores[row * N + k] * V[k * d + col];
}
output[row * d + col] = sum;
}
// Q, K, V, output are device pointers
extern "C" void solve(const float *Q, const float *K, const float *V,
float *output, int M, int N, int d) {
// Allocate temporary Scores buffer [M, N]
float *Scores;
CUDA_CHECK(cudaMalloc(&Scores, M * N * sizeof(float)));
// === Kernel 1: Q * K^T ===
dim3 block_qk(16, 16);
dim3 grid_qk((N + 15) / 16, (M + 15) / 16);
matmul_qk<<<grid_qk, block_qk>>>(Q, K, Scores, M, N, d);
CUDA_CHECK(cudaGetLastError());
// === Kernel 2: Softmax ===
const int softmax_block_size = 256; // Tune based on N
size_t shared_mem_size = softmax_block_size * sizeof(float);
softmax_kernel<<<M, softmax_block_size, shared_mem_size>>>(Scores, M, N);
CUDA_CHECK(cudaGetLastError());
// === Kernel 3: Scores * V ===
dim3 block_sv(16, 16);
dim3 grid_sv((d + 15) / 16, (M + 15) / 16);
matmul_sv<<<grid_sv, block_sv>>>(Scores, V, output, M, N, d);
CUDA_CHECK(cudaGetLastError());
CUDA_CHECK(cudaDeviceSynchronize());
CUDA_CHECK(cudaFree(Scores));
}
2D Convolution
import torch
# input, kernel, output are tensors on the GPU
def solve(
input: torch.Tensor,
kernel: torch.Tensor,
output: torch.Tensor,
input_rows: int,
input_cols: int,
kernel_rows: int,
kernel_cols: int,
):
input = input.reshape(1, 1, input_rows, input_cols)
kernel = kernel.reshape(1, 1, kernel_rows, kernel_cols)
output.copy_(torch.nn.functional.conv2d(input=input, weight=kernel).view_as(output))
#include <cuda_runtime.h>
#define TILE_X 16
#define TILE_Y 16
#define MAX_KERNEL_DIM 31
#define MAX_KERNEL_SIZE (MAX_KERNEL_DIM * MAX_KERNEL_DIM)
__constant__ float kernel_const[MAX_KERNEL_SIZE];
__global__ void conv2d_kernel(const float *input, float *output, int input_rows,
int input_cols, int kernel_rows, int kernel_cols,
int output_rows, int output_cols) {
int tx = threadIdx.x;
int ty = threadIdx.y;
int in_x = blockIdx.x * TILE_X;
int in_y = blockIdx.y * TILE_Y;
int out_x = in_x + tx;
int out_y = in_y + ty;
int smem_width = TILE_X + kernel_cols - 1;
int smem_height = TILE_Y + kernel_rows - 1;
extern __shared__ float s_mem[];
// Load input data into shared memory
int total_elements = smem_height * smem_width;
int total_threads = TILE_X * TILE_Y;
for (int i = 0; i < total_elements; i += total_threads) {
int idx = i + TILE_X * ty + tx;
if (idx < total_elements) {
int s_y = idx / smem_width;
int s_x = idx % smem_width;
int g_x = in_x + s_x;
int g_y = in_y + s_y;
if (g_y < input_rows && g_x < input_cols) {
s_mem[idx] = input[g_y * input_cols + g_x];
} else {
s_mem[idx] = 0.0f;
}
}
}
__syncthreads();
if (out_y < output_rows && out_x < output_cols) {
float sum = 0.0f;
for (int m = 0; m < kernel_rows; ++m) {
for (int n = 0; n < kernel_cols; ++n) {
int s_idx = (ty + m) * smem_width + (tx + n);
int k_idx = m * kernel_cols + n;
sum += s_mem[s_idx] * kernel_const[k_idx];
}
}
output[out_y * output_cols + out_x] = sum;
}
}
extern "C" void solve(const float *input, const float *kernel, float *output,
int input_rows, int input_cols, int kernel_rows,
int kernel_cols) {
int output_rows = input_rows - kernel_rows + 1;
int output_cols = input_cols - kernel_cols + 1;
if (output_rows <= 0 || output_cols <= 0) {
return;
}
// 1 <= kernel_rows, kernel_cols <= 31
int kernel_size = kernel_rows * kernel_cols;
cudaMemcpyToSymbol(kernel_const, kernel, kernel_size * sizeof(float));
dim3 block(TILE_X, TILE_Y);
dim3 grid((output_cols + TILE_X - 1) / TILE_X,
(output_rows + TILE_Y - 1) / TILE_Y);
// Halo
int smem_width = TILE_X + kernel_cols - 1;
int smem_height = TILE_Y + kernel_rows - 1;
size_t smem_size = smem_width * smem_height * sizeof(float);
conv2d_kernel<<<grid, block, smem_size>>>(
input, output, input_rows, input_cols, kernel_rows, kernel_cols,
output_rows, output_cols);
}